Chapter 10 Convolutional neural networks
The first neural networks we built in Chapter 8 did not have the capacity to learn much about structure, sequences, or long-range dependencies in our text data. The LSTM networks we trained in Chapter 9 were especially suited to learning long-range dependencies. In this final chapter, we will focus on convolutional neural network (CNN) architecture (Yoon Kim 2014), which can learn local, spatial structure within data.
CNNs can be well-suited for modeling text data because text often contains quite a lot of local structure. A CNN does not learn long-range structure within a sequence like an LSTM, but instead detects local patterns. A CNN network layer takes data (like text) as input and then hopefully produces output that represents specific structures in the data.
Let’s take more time with CNNs in this chapter to explore their construction, different features, and the hyperparameters we can tune.
10.1 What are CNNs?
CNNs can work with data of different dimensions (like two-dimensional images or three-dimensional video), but for text modeling, we typically work in one dimension. The illustrations and explanations in this chapter use only one dimension to match the text use case. Figure 10.1 illustrates a typical CNN architecture. A convolutional filter slides along the sequence to produce a new, smaller sequence. This is repeated multiple times, typically with different parameters for each layer, until we are left with a small data cube that we can transform into our required output shape, a value between 0 and 1 in the case of binary classification.
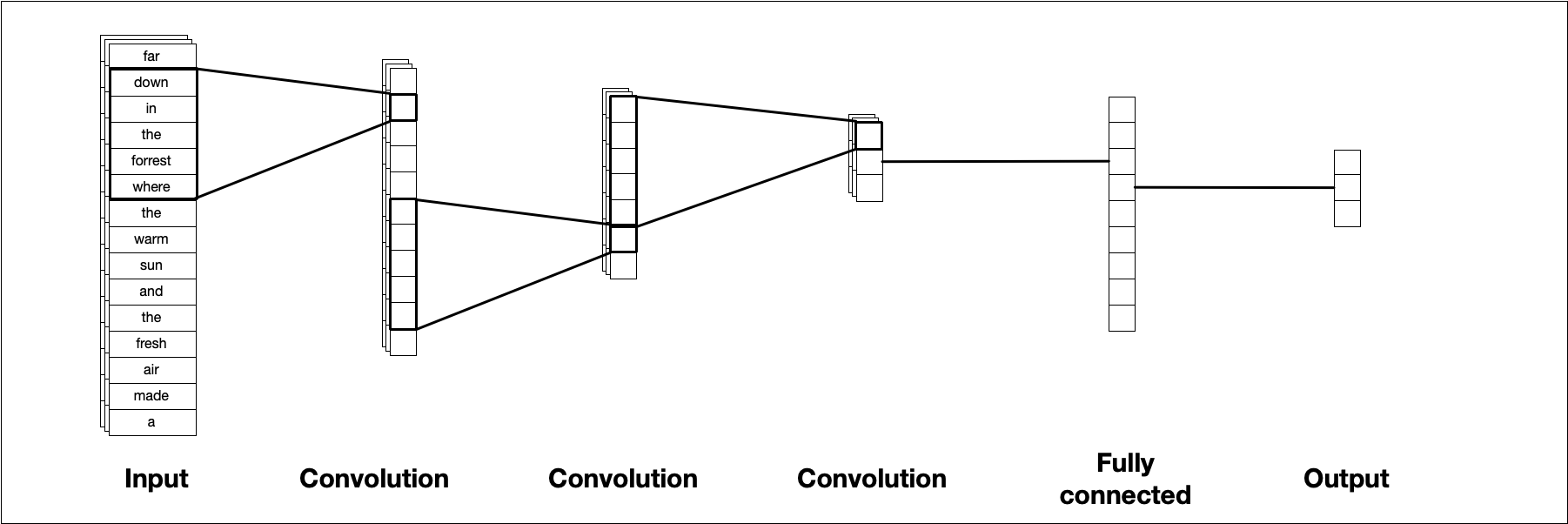
FIGURE 10.1: A template CNN architecture for one-dimensional input data. A sequence of consecutive CNN layers incremently reduces the size, ending with single output value.
This figure isn’t entirely accurate because we technically don’t feed characters into a CNN, but instead use one-hot sequence encoding (Section 8.2.2) with a possible word embedding. Let’s talk about two of the most important CNN concepts, kernels and kernel size.
10.1.1 Kernel
The kernel is a small vector that slides along the input. When it is sliding, it performs element-wise multiplication of the values in the input and its own weights, and then sums up the values to get a single value.
Sometimes an activation function is applied as well.
It is these weights that are trained via gradient descent to find the best fit.
In Keras, the filters represent how many different kernels are trained in each layer. You typically start with fewer filters at the beginning of your network and then increase them as you go along.
10.1.2 Kernel size
The most prominent hyperparameter is the kernel size. The kernel size is the length of the vector that contains the weights. A kernel of size 5 will have 5 weights. These kernels can capture local information similarly to how n-grams capture location patterns. Increasing the size of the kernel decreases the size of the output, as shown in Figure 10.2.
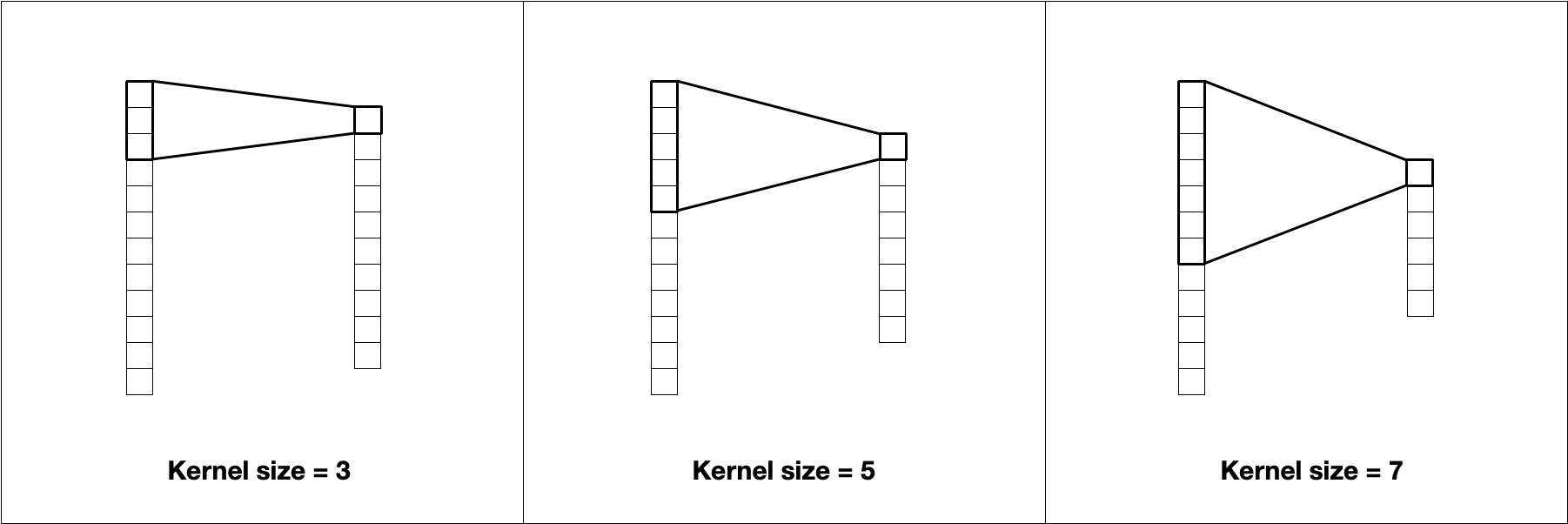
FIGURE 10.2: The kernel size affects the size of the output. A kernel size of 3 uses the information from 3 values to compute 1 value.
Larger kernels learn larger and less frequent patterns, while smaller kernels will find fine-grained features. Notice how the choice of token affects how we think about kernel size. For character tokenization, a kernel size of 5 will (in early layers) find patterns in subwords more often than patterns across words, since 5 characters will typically not span multiple words. By contrast, a kernel size of 5 with word tokenization will learn patterns within sentences instead.
10.2 A first CNN model
We will be using the same data, which we examine in Sections 8.1 and B.4 and use throughout Chapters 8 and 9. This data set contains short text blurbs for prospective crowdfunding campaigns on Kickstarter, along with if they were successful. Our goal of this modeling is to predict successful campaigns from the text contained in the blurb. We will also use the same preprocessing and feature engineering recipe that we created and described in Sections 8.2.1 and 9.1.
Our first CNN will look a lot like what is shown in Figure 10.1.
We start with an embedding layer, followed by a single one-dimensional convolution layer layer_conv_1d(), then a global max pooling layer layer_global_max_pooling_1d(), a densely connected layer, and end with a dense layer with a sigmoid activation function to give us one value between 0 and 1 to use in our binary classification task.
library(keras)
simple_cnn_model <- keras_model_sequential() %>%
layer_embedding(input_dim = max_words + 1, output_dim = 16,
input_length = max_length) %>%
layer_conv_1d(filter = 32, kernel_size = 5, activation = "relu") %>%
layer_global_max_pooling_1d() %>%
layer_dense(units = 64, activation = "relu") %>%
layer_dense(units = 1, activation = "sigmoid")
simple_cnn_model#> Model: "sequential"
#> ________________________________________________________________________________
#> Layer (type) Output Shape Param #
#> ================================================================================
#> embedding (Embedding) (None, 30, 16) 320016
#> ________________________________________________________________________________
#> conv1d (Conv1D) (None, 26, 32) 2592
#> ________________________________________________________________________________
#> global_max_pooling1d (GlobalMaxPool (None, 32) 0
#> ________________________________________________________________________________
#> dense_1 (Dense) (None, 64) 2112
#> ________________________________________________________________________________
#> dense (Dense) (None, 1) 65
#> ================================================================================
#> Total params: 324,785
#> Trainable params: 324,785
#> Non-trainable params: 0
#> ________________________________________________________________________________We are using the same embedding layer with the same max_length as in the previous networks so there is nothing new there.
The layer_global_max_pooling_1d() layer collapses the remaining CNN output into one dimension so we can finish it off with a densely connected layer and the sigmoid activation function.
This might not end up being the best CNN configuration, but it is a good starting point.
One of the challenges when working with CNNs is to ensure that we manage the dimensionality correctly. The length of the sequence decreases by (kernel_size - 1) for each layer. For this input, we have a sequence of length max_length = 30, which is decreased by (5 - 1) = 4 resulting in a sequence of 26, as shown in the printed output of simple_cnn_model. We could create seven layers with kernel_size = 5, since we would end with 30 - 4 - 4 - 4 - 4 - 4 - 4 - 4 = 2 elements in the resulting sequence. However, we would not be able to do a network with 3 layers of
kernel_size = 7 followed by 3 layers of kernel_size = 5 since the resulting sequence would be 30 - 6 - 6 - 6 - 4 - 4 - 4 = 0 and we must have a positive length for our sequence.
Remember that kernel_size is not the only argument that will change the length of the resulting sequence.
Constructing a sequence layer by layer and using the print method from keras to check the configuration is a great way to make sure your architecture is valid.
The compilation and fitting are the same as we have seen before, using a validation split created with tidymodels as shown in Sections 8.2.4 and 9.1.2.
simple_cnn_model %>% compile(
optimizer = "adam",
loss = "binary_crossentropy",
metrics = c("accuracy")
)
cnn_history <- simple_cnn_model %>% fit(
x = kick_analysis,
y = state_analysis,
batch_size = 512,
epochs = 10,
validation_data = list(kick_assess, state_assess)
)
We are using the “adam” optimizer since it performs well for many kinds of models. You may have to experiment to find the optimizer that works best for your model and data.
Now that the model is done fitting, we can evaluate it on the validation data set using the same keras_predict() function we created in Section 8.2.4 and used throughout Chapters 8 and 9.
val_res <- keras_predict(simple_cnn_model, kick_assess, state_assess)
val_res#> # A tibble: 50,524 × 3
#> .pred_1 .pred_class state
#> <dbl> <fct> <fct>
#> 1 0.0550 0 0
#> 2 0.00495 0 0
#> 3 0.000920 0 0
#> 4 0.252 0 0
#> 5 1 1 1
#> 6 0.999 1 1
#> 7 0.000249 0 0
#> 8 0.0217 0 0
#> 9 0.258 0 1
#> 10 1 1 1
#> # … with 50,514 more rowsWe can calculate some standard metrics with metrics().
metrics(val_res, state, .pred_class, .pred_1)#> # A tibble: 4 × 3
#> .metric .estimator .estimate
#> <chr> <chr> <dbl>
#> 1 accuracy binary 0.811
#> 2 kap binary 0.623
#> 3 mn_log_loss binary 0.936
#> 4 roc_auc binary 0.864We already see improvement over the densely connected network from Chapter 8, our best performing model on the Kickstarter data so far.
The heatmap in Figure 10.3 shows that the model performs about the same for the two classes, success and failure for the crowdfunding campaigns; we are getting fairly good results from a baseline CNN model!
val_res %>%
conf_mat(state, .pred_class) %>%
autoplot(type = "heatmap")
FIGURE 10.3: Confusion matrix for first CNN model predictions of Kickstarter campaign success
The ROC curve in Figure 10.4 shows how the model performs at different thresholds.
val_res %>%
roc_curve(truth = state, .pred_1) %>%
autoplot() +
labs(
title = "Receiver operator curve for Kickstarter blurbs"
)
FIGURE 10.4: ROC curve for first CNN model predictions of Kickstarter campaign success
10.3 Case study: adding more layers
Now that we know how our basic CNN performs, we can see what happens when we apply some common modifications to it. This case study will examine:
how we can add additional convolutional layers to our base model and
how additional dense layers can be added.
Let’s start by adding another fully connected layer. We take the architecture we used in simple_cnn_model and add another layer_dense() after the first layer_dense() in the model.
Increasing the depth of the model via the fully connected layers allows the model to find more complex patterns.
There is, however, a trade-off. Adding more layers adds more weights to the model, making it more complex and harder to train. If you don’t have enough data or the patterns you are trying to classify aren’t that complex, then model performance will suffer since the model will start overfitting as it starts memorizing patterns in the training data that don’t generalize to new data.
When working with CNNs, the different layers perform different tasks. A convolutional layer extracts local patterns as it slides along the sequences, while a fully connected layer finds global patterns.
We can think of the convolutional layers as doing preprocessing on the text, which is then fed into the dense neural network that tries to fit the best curve. Adding more fully connected layers allows the network to create more intricate curves, and adding more convolutional layers creates richer features that are used when fitting the curves. Your job when constructing a CNN is to make the architecture just complex enough to match the data without overfitting. One ad-hoc rule to follow when refining your network architecture is to start small and keep adding layers until the validation error does not improve anymore.
cnn_double_dense <- keras_model_sequential() %>%
layer_embedding(input_dim = max_words + 1, output_dim = 16,
input_length = max_length) %>%
layer_conv_1d(filter = 32, kernel_size = 5, activation = "relu") %>%
layer_global_max_pooling_1d() %>%
layer_dense(units = 64, activation = "relu") %>%
layer_dense(units = 64, activation = "relu") %>%
layer_dense(units = 1, activation = "sigmoid")
cnn_double_dense#> Model: "sequential_1"
#> ________________________________________________________________________________
#> Layer (type) Output Shape Param #
#> ================================================================================
#> embedding_1 (Embedding) (None, 30, 16) 320016
#> ________________________________________________________________________________
#> conv1d_1 (Conv1D) (None, 26, 32) 2592
#> ________________________________________________________________________________
#> global_max_pooling1d_1 (GlobalMaxPo (None, 32) 0
#> ________________________________________________________________________________
#> dense_4 (Dense) (None, 64) 2112
#> ________________________________________________________________________________
#> dense_3 (Dense) (None, 64) 4160
#> ________________________________________________________________________________
#> dense_2 (Dense) (None, 1) 65
#> ================================================================================
#> Total params: 328,945
#> Trainable params: 328,945
#> Non-trainable params: 0
#> ________________________________________________________________________________We can compile and fit this new model. We will try to keep as much as we can constant as we compare the different models.
cnn_double_dense %>% compile(
optimizer = "adam",
loss = "binary_crossentropy",
metrics = c("accuracy")
)
history <- cnn_double_dense %>% fit(
x = kick_analysis,
y = state_analysis,
batch_size = 512,
epochs = 10,
validation_data = list(kick_assess, state_assess)
)val_res_double_dense <- keras_predict(
cnn_double_dense,
kick_assess,
state_assess
)
metrics(val_res_double_dense, state, .pred_class, .pred_1)#> # A tibble: 4 × 3
#> .metric .estimator .estimate
#> <chr> <chr> <dbl>
#> 1 accuracy binary 0.810
#> 2 kap binary 0.620
#> 3 mn_log_loss binary 1.01
#> 4 roc_auc binary 0.858This model performs well, but it is not entirely clear that it is working much better than the first CNN model we tried. This could be an indication that the original model had enough fully connected layers for the amount of training data we have available.
If we have two models with nearly identical performance, we should choose the less complex of the two, since it will have faster performance.
We can also change the number of convolutional layers, by adding more such layers.
cnn_double_conv <- keras_model_sequential() %>%
layer_embedding(input_dim = max_words + 1, output_dim = 16,
input_length = max_length) %>%
layer_conv_1d(filter = 32, kernel_size = 5, activation = "relu") %>%
layer_max_pooling_1d(pool_size = 2) %>%
layer_conv_1d(filter = 64, kernel_size = 3, activation = "relu") %>%
layer_global_max_pooling_1d() %>%
layer_dense(units = 64, activation = "relu") %>%
layer_dense(units = 1, activation = "sigmoid")
cnn_double_conv#> Model: "sequential_2"
#> ________________________________________________________________________________
#> Layer (type) Output Shape Param #
#> ================================================================================
#> embedding_2 (Embedding) (None, 30, 16) 320016
#> ________________________________________________________________________________
#> conv1d_3 (Conv1D) (None, 26, 32) 2592
#> ________________________________________________________________________________
#> max_pooling1d (MaxPooling1D) (None, 13, 32) 0
#> ________________________________________________________________________________
#> conv1d_2 (Conv1D) (None, 11, 64) 6208
#> ________________________________________________________________________________
#> global_max_pooling1d_2 (GlobalMaxPo (None, 64) 0
#> ________________________________________________________________________________
#> dense_6 (Dense) (None, 64) 4160
#> ________________________________________________________________________________
#> dense_5 (Dense) (None, 1) 65
#> ================================================================================
#> Total params: 333,041
#> Trainable params: 333,041
#> Non-trainable params: 0
#> ________________________________________________________________________________There are a lot of different ways we can extend the network by adding convolutional layers with layer_conv_1d(). We must consider the individual characteristics of each layer, with respect to kernel size, as well as other CNN parameters we have not discussed in detail yet like stride, padding, and dilation rate. We also have to consider the progression of these layers within the network itself.
The model is using an increasing number of filters in each layer, doubling the number of filters for each layer. This is to ensure that there are more filters later on to capture enough of the global information.
This model is using a kernel size of 5 twice. There aren’t any hard rules about how you structure kernel sizes, but the sizes you choose will change what features the model can detect.
The early layers extract general or low-level features while the later layers learn finer detail or high-level features in the data. The choice of kernel size determines the size of these features.
Having a small kernel size in the first layer will let the model detect low-level features locally.
We are also including a max-pooling layer with layer_max_pooling_1d() between the convolutional layers. This layer performs a pooling operation that calculates the maximum values in its pooling window; in this model, that is set to 2.
This is done in the hope that the pooled features will be able to perform better by weeding out the small weights.
This is another parameter you can tinker with when you are designing the network.
We compile this model like the others, again trying to keep as much as we can constant. The only thing that changed in this model compared to the first is the addition of a layer_max_pooling_1d() and a layer_conv_1d().
cnn_double_conv %>% compile(
optimizer = "adam",
loss = "binary_crossentropy",
metrics = c("accuracy")
)
history <- cnn_double_conv %>% fit(
x = kick_analysis,
y = state_analysis,
batch_size = 512,
epochs = 10,
validation_data = list(kick_assess, state_assess)
)val_res_double_conv <- keras_predict(
cnn_double_conv,
kick_assess,
state_assess
)
metrics(val_res_double_conv, state, .pred_class, .pred_1)#> # A tibble: 4 × 3
#> .metric .estimator .estimate
#> <chr> <chr> <dbl>
#> 1 accuracy binary 0.801
#> 2 kap binary 0.600
#> 3 mn_log_loss binary 1.04
#> 4 roc_auc binary 0.852This model also performs well compared to earlier results. Let us extract the the prediction using keras_predict() we defined in Section 8.2.4.
all_cnn_model_predictions <- bind_rows(
mutate(val_res, model = "Basic CNN"),
mutate(val_res_double_dense, model = "Double Dense"),
mutate(val_res_double_conv, model = "Double Conv")
)
all_cnn_model_predictions#> # A tibble: 151,572 × 4
#> .pred_1 .pred_class state model
#> <dbl> <fct> <fct> <chr>
#> 1 0.0550 0 0 Basic CNN
#> 2 0.00495 0 0 Basic CNN
#> 3 0.000920 0 0 Basic CNN
#> 4 0.252 0 0 Basic CNN
#> 5 1 1 1 Basic CNN
#> 6 0.999 1 1 Basic CNN
#> 7 0.000249 0 0 Basic CNN
#> 8 0.0217 0 0 Basic CNN
#> 9 0.258 0 1 Basic CNN
#> 10 1 1 1 Basic CNN
#> # … with 151,562 more rowsNow that the results are combined in all_cnn_model_predictions we can calculate group-wise evaluation statistics by grouping them by the model variable.
all_cnn_model_predictions %>%
group_by(model) %>%
metrics(state, .pred_class, .pred_1)#> # A tibble: 12 × 4
#> model .metric .estimator .estimate
#> <chr> <chr> <chr> <dbl>
#> 1 Basic CNN accuracy binary 0.811
#> 2 Double Conv accuracy binary 0.801
#> 3 Double Dense accuracy binary 0.810
#> 4 Basic CNN kap binary 0.623
#> 5 Double Conv kap binary 0.600
#> 6 Double Dense kap binary 0.620
#> 7 Basic CNN mn_log_loss binary 0.936
#> 8 Double Conv mn_log_loss binary 1.04
#> 9 Double Dense mn_log_loss binary 1.01
#> 10 Basic CNN roc_auc binary 0.864
#> 11 Double Conv roc_auc binary 0.852
#> 12 Double Dense roc_auc binary 0.858We can also compute ROC curves for all our models so far. Figure 10.5 shows the three different ROC curves together in one chart.
all_cnn_model_predictions %>%
group_by(model) %>%
roc_curve(truth = state, .pred_1) %>%
autoplot() +
labs(
title = "Receiver operator curve for Kickstarter blurbs"
)
FIGURE 10.5: ROC curve for three CNN variants’ predictions of Kickstarter campaign success
The curves are very close in this chart, indicating that we don’t have much to gain by adding more layers and that they don’t improve performance substantively. This doesn’t mean that we are done with CNNs! There are still many things we can explore, like different tokenization approaches and hyperparameters that can be trained.
10.4 Case study: byte pair encoding
In our models in this chapter so far we have used words as the token of interest. We saw in Section 6.5 how n-grams can be used in modeling as well. One of the reasons why the Kickstarter data set is hard to work with is because the text is quite short so we don’t have that many individual tokens to work with in a given blurb. Another choice of token is subwords, where we split the text into smaller units than words; longer words especially will be broken into multiple subword units. One way to tokenize text into subword units is byte pair encoding (Gage 1994). This algorithm has been repurposed to work on text by iteratively merging frequently occurring subword pairs. Methods such as BERT and GPT-2 use subword units for text with great success. The byte pair encoding algorithm has a hyperparameter controlling the size of the vocabulary. Setting it to higher values allows the models to find more rarely used character sequences in the text.
Byte pair encoding offers a good trade-off between character-level and word-level information, and can also encode unknown words. For example, suppose that the model is aware of the word “woman.” A simple tokenizer would have to put a word such as “womanhood” into an unknown bucket or ignore it completely, whereas byte pair encoding should be able to pick up on the subwords “woman” and “hood” (or “woman,” “h,” and “ood,” depending on whether the model found “hood” as a common enough subword). Using a subword tokenizer such as byte pair encoding should let us see the text with more granularity since we will have more and smaller tokens for each observation.
We need to remind ourselves that these models don’t contain any linguistic knowledge at all; they only “learn” the morphological patterns of sequences of characters (Section 1.2) in the training set. This does not make the models useless, but it should set our expectations about what any given model is capable of.
Since we are using a completely different preprocessing approach, we need to specify a new feature engineering recipe.
The textrecipes package has a tokenization engine to perform byte pair encoding, but we need to determine the vocabulary size and the appropriate sequence length.
Let’s write a function that takes a character vector and a vocabulary size and returns a dataframe with the number of tokens in each observation.
library(textrecipes)
get_bpe_token_dist <- function(vocab_size, x) {
recipe(~text, data = tibble(text = x)) %>%
step_mutate(text = tolower(text)) %>%
step_tokenize(text,
engine = "tokenizers.bpe",
training_options = list(vocab_size = vocab_size)) %>%
prep() %>%
bake(new_data = NULL) %>%
transmute(n_tokens = lengths(textrecipes:::get_tokens(text)),
vocab_size = vocab_size)
}We can use map() to try a handful of different vocabulary sizes.
bpe_token_dist <- map_dfr(
c(2500, 5000, 10000, 20000),
get_bpe_token_dist,
kickstarter_train$blurb
)
bpe_token_dist#> # A tibble: 808,368 × 2
#> n_tokens vocab_size
#> <int> <dbl>
#> 1 16 2500
#> 2 34 2500
#> 3 22 2500
#> 4 26 2500
#> 5 13 2500
#> 6 19 2500
#> 7 33 2500
#> 8 24 2500
#> 9 35 2500
#> 10 37 2500
#> # … with 808,358 more rowsIf we compare with the word count distribution we saw in Figure 8.4, then we see in Figure 10.6 that any of these choices for vocabulary size will result in more tokens overall.
bpe_token_dist %>%
ggplot(aes(n_tokens)) +
geom_bar() +
facet_wrap(~vocab_size) +
labs(x = "Number of subwords per campaign blurb",
y = "Number of campaign blurbs")
FIGURE 10.6: Distribution of subword count for Kickstarter campaign blurbs for different vocabulary sizes
Let’s pick a vocabulary size of 10,000 and a corresponding sequence length of 40. To use byte pair encoding as a tokenizer in textrecipes set engine = "tokenizers.bpe"; the vocabulary size can be denoted using the training_options argument. Everything else in the recipe stays the same.
max_subwords <- 10000
bpe_max_length <- 40
bpe_rec <- recipe(~blurb, data = kickstarter_train) %>%
step_mutate(blurb = tolower(blurb)) %>%
step_tokenize(blurb,
engine = "tokenizers.bpe",
training_options = list(vocab_size = max_subwords)) %>%
step_sequence_onehot(blurb, sequence_length = bpe_max_length)
bpe_prep <- prep(bpe_rec)
bpe_analysis <- bake(bpe_prep, new_data = analysis(kick_val$splits[[1]]),
composition = "matrix")
bpe_assess <- bake(bpe_prep, new_data = assessment(kick_val$splits[[1]]),
composition = "matrix")Our model will be very similar to the baseline CNN model from Section 10.2; we’ll use a larger kernel size of 7 to account for the finer detail in the tokens.
cnn_bpe <- keras_model_sequential() %>%
layer_embedding(input_dim = max_words + 1, output_dim = 16,
input_length = bpe_max_length) %>%
layer_conv_1d(filter = 32, kernel_size = 7, activation = "relu") %>%
layer_global_max_pooling_1d() %>%
layer_dense(units = 64, activation = "relu") %>%
layer_dense(units = 1, activation = "sigmoid")
cnn_bpe#> Model: "sequential_3"
#> ________________________________________________________________________________
#> Layer (type) Output Shape Param #
#> ================================================================================
#> embedding_3 (Embedding) (None, 40, 16) 320016
#> ________________________________________________________________________________
#> conv1d_4 (Conv1D) (None, 34, 32) 3616
#> ________________________________________________________________________________
#> global_max_pooling1d_3 (GlobalMaxPo (None, 32) 0
#> ________________________________________________________________________________
#> dense_8 (Dense) (None, 64) 2112
#> ________________________________________________________________________________
#> dense_7 (Dense) (None, 1) 65
#> ================================================================================
#> Total params: 325,809
#> Trainable params: 325,809
#> Non-trainable params: 0
#> ________________________________________________________________________________We can compile and train like we have done so many times now.
cnn_bpe %>% compile(
optimizer = "adam",
loss = "binary_crossentropy",
metrics = c("accuracy")
)
bpe_history <- cnn_bpe %>% fit(
bpe_analysis,
state_analysis,
epochs = 10,
validation_data = list(bpe_assess, state_assess),
batch_size = 512
)
bpe_history#>
#> Final epoch (plot to see history):
#> loss: 0.03079
#> accuracy: 0.9949
#> val_loss: 0.9939
#> val_accuracy: 0.8111The performance is doing quite well, which is a pleasant surprise! This is what we hoped would happen if we switched to a higher-detail tokenizer.
The confusion matrix in Figure 10.7 also clearly shows that there isn’t much bias between the two classes with this new tokenizer.
val_res_bpe <- keras_predict(cnn_bpe, bpe_assess, state_assess)
val_res_bpe %>%
conf_mat(state, .pred_class) %>%
autoplot(type = "heatmap")
FIGURE 10.7: Confusion matrix for CNN model using byte pair encoding tokenization
What are the subwords being used in this model? We can extract them from step_sequence_onehot() using tidy() on the prepped recipe. All the tokens that start with an "h" are seen here.
bpe_rec %>%
prep() %>%
tidy(3) %>%
filter(str_detect(token, "^h")) %>%
pull(token)#> [1] "h" "ha" "hab" "hal" "ham" "hand" "he"
#> [8] "head" "heart" "hearted" "heast" "hed" "hedul" "heim"
#> [15] "hel" "help" "hem" "hen" "hent" "her" "here"
#> [22] "hern" "hero" "hes" "hes," "hes." "hest" "het"
#> [29] "hetic" "hett" "hib" "hic" "hing" "hing." "hip"
#> [36] "hist" "hn" "hol" "hold" "hood" "hop" "hor"
#> [43] "hous" "house" "how" "hr" "hs" "hu"Notice how some of these subword tokens are full words, and some are parts of words. This is what allows the model to be able to “read” long unknown words by combining many smaller subwords. We can also look at common long words.
bpe_rec %>%
prep() %>%
tidy(3) %>%
arrange(desc(nchar(token))) %>%
slice_head(n = 25) %>%
pull(token)#> [1] "▁singer-songwriter" "▁singer/songwriter" "▁post-apocalyptic"
#> [4] "▁interchangeable" "▁singer/songwrit" "▁entertainment."
#> [7] "▁feature-length" "▁groundbreaking" "▁illustrations."
#> [10] "▁professionally" "▁relationships." "▁self-published"
#> [13] "▁sustainability" "▁transformation" "▁unconventional"
#> [16] "▁architectural" "▁automatically" "▁award-winning"
#> [19] "▁collaborating" "▁collaboration" "▁collaborative"
#> [22] "▁coming-of-age" "▁communication" "▁comprehensive"
#> [25] "▁consciousness"These 25 words were common enough to get their own subword token, and helps us understand the nature of these Kickstarter crowdfunding campaigns.
Examining the longest subword tokens gives you a good sense of the data you are working with!
10.5 Case study: explainability with LIME
We noted in Section 8.7 that one of the significant limitations of deep learning models is that they are hard to reason about. One of the ways to understand a predictive model, even a “black box” one, is using an algorithm for observation-level variable importance like the Local Interpretable Model-Agnostic Explanations (Ribeiro, Singh, and Guestrin 2016) algorithm, or LIME for short.
As indicated by its name, LIME is an approach to compute local feature importance, or explainability at the individual observation level. It does not offer global feature importance, or explainability for the model as a whole.
To use this package we need to write a helper function to get the data in the format we want. The lime() function takes two mandatory arguments, x and model. The model argument is the trained model we are trying to explain. The lime() function works out of the box with Keras models so we should be good to go there. The x argument is the training data used for training the model. This is where we need to to create a helper function; the lime package is expecting x to be a character vector so we’ll need a function that takes a character vector as input and returns the matrix the Keras model is expecting.
kick_prepped_rec <- prep(kick_rec)
text_to_matrix <- function(x) {
bake(
kick_prepped_rec,
new_data = tibble(blurb = x),
composition = "matrix"
)
}
Since the function needs to be able to work with just the x parameter alone, we need to put prepped_recipe inside the function rather than passing it in as an argument. This will work with R’s scoping rules but does require you to create a new function for each recipe.
Let’s select a couple of training observations to explain.
sentence_to_explain <- kickstarter_train %>%
slice(c(1, 5)) %>%
pull(blurb)
sentence_to_explain#> [1] "The new way of learning English made simple, interesting and practical!"
#> [2] "Happiness in a jar has finally been reached."We now load the lime package and pass observations into lime() along with the model we are trying to explain and the preprocess function.
Be sure that the preprocessing function matches the preprocessing that was used to train the model.
library(lime)
explainer <- lime(
x = sentence_to_explain,
model = simple_cnn_model,
preprocess = text_to_matrix
)This explainer object can now be used with explain() to generate explanations for the sentences. We set n_labels = 1 to only get explanations for the first label, since we are working with a binary classification model15. We set n_features = 12 to return the 12 most important features. If we were dealing with longer text, we might want to change n_features to return more features (tokens).
explanation <- explain(
x = sentence_to_explain,
explainer = explainer,
n_labels = 1,
n_features = 12
)
explanation#> # A tibble: 19 × 13
#> model_type case label label_prob model_r2 model_intercept model_prediction
#> * <chr> <int> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 classificat… 1 1 0.993 0.322 0.773 0.775
#> 2 classificat… 1 1 0.993 0.322 0.773 0.775
#> 3 classificat… 1 1 0.993 0.322 0.773 0.775
#> 4 classificat… 1 1 0.993 0.322 0.773 0.775
#> 5 classificat… 1 1 0.993 0.322 0.773 0.775
#> 6 classificat… 1 1 0.993 0.322 0.773 0.775
#> 7 classificat… 1 1 0.993 0.322 0.773 0.775
#> 8 classificat… 1 1 0.993 0.322 0.773 0.775
#> 9 classificat… 1 1 0.993 0.322 0.773 0.775
#> 10 classificat… 1 1 0.993 0.322 0.773 0.775
#> 11 classificat… 1 1 0.993 0.322 0.773 0.775
#> 12 classificat… 2 1 0.996 0.437 0.518 0.960
#> 13 classificat… 2 1 0.996 0.437 0.518 0.960
#> 14 classificat… 2 1 0.996 0.437 0.518 0.960
#> 15 classificat… 2 1 0.996 0.437 0.518 0.960
#> 16 classificat… 2 1 0.996 0.437 0.518 0.960
#> 17 classificat… 2 1 0.996 0.437 0.518 0.960
#> 18 classificat… 2 1 0.996 0.437 0.518 0.960
#> 19 classificat… 2 1 0.996 0.437 0.518 0.960
#> # … with 6 more variables: feature <chr>, feature_value <chr>,
#> # feature_weight <dbl>, feature_desc <chr>, data <chr>, prediction <list>The output comes in a tibble format where feature and feature_weight are included, but fortunately lime contains some functions to visualize these weights. Figure 10.8 shows the result of using plot_features(), with each facet containing an observation-label pair and the bars showing the weight of the different tokens. Bars in the positive direction (darker) indicate that the weights support the prediction and bars in the negative direction (lighter) indicate contradictions. This chart is great for finding the most prominent features in an observation.
plot_features(explanation)
FIGURE 10.8: Plot of most important features for a CNN model predicting two observations.
Figure 10.9 shows the weights by highlighting the words directly in the text. This gives us a way to see if any local patterns contain a lot of weight.
plot_text_explanations(explanation)FIGURE 10.9: Feature highlighting of words for two examples explained by a CNN model.
The interactive_text_explanations() function can be used to launch an interactive Shiny app where you can explore the model weights.
One of the ways a deep learning model is hard to explain is that changes to a part of the input can affect how the input is being used as a whole. Remember that in bag-of-words models adding another token when predicting would just add another unit in the weight; this is not always the case when using deep learning models.
The following example shows this effect. We have created two very similar sentences in fake_sentences.
fake_sentences <- c(
"Fun and exciting dice game for the whole family",
"Fun and exciting dice game for the family"
)
explainer <- lime(
x = fake_sentences,
model = simple_cnn_model,
preprocess = text_to_matrix
)
explanation <- explain(
x = fake_sentences,
explainer = explainer,
n_labels = 1,
n_features = 12
)Explanations based on these two sentences are fairly similar as we can see in Figure 10.10. However, notice how the removal of the word “whole” affects the weights of the other words in the examples, in some cases switching the sign from supporting to contradicting.
plot_text_explanations(explanation)FIGURE 10.10: Feature highlighting of words in two examples explained by a CNN model.
It is these kinds of correlated patterns that can make deep learning models hard to reason about and can deliver surprising results.
The LIME algorithm and lime R package are not limited to explaining CNNs. This approach can be used with any of the models we have used in this book, even the ones trained with parsnip.
10.6 Case study: hyperparameter search
So far in all our deep learning models, we have only used one configuration of hyperparameters. Sometimes we want to try different hyperparameters out and find what works best for our model like we did in Sections 6.9 and 7.11 using the tune package. We can use the tfruns package to run multiple Keras models and compare the results.
This workflow will be a little different than what we have seen in the book so far since we will have to create a .R file that contains the necessary modeling steps and then use that file to fit multiple models. Such an example file named cnn-spec.R used for the following models is available on GitHub. The first thing we need to do is specify what hyperparameters we want to vary. By convention, this object is named FLAGS and it is created using the flags() function. For each parameter we want to tune, we add a corresponding flag_*() function, which can be flag_integer(), flag_boolean(), flag_numeric(), or flag_string() depending on what we need to tune.
Be sure you are using the right type for each of these flags; Keras is quite picky! If Keras is expecting an integer and gets a numeric then you will get an error.
FLAGS <- flags(
flag_integer("kernel_size1", 5),
flag_integer("strides1", 1)
)Notice how we are giving each flag a name and a possible value. The value itself isn’t important, as it is not used once we start running multiple models, but it needs to be the right type for the model we are using.
Next, we specify the Keras model we want to run.
model <- keras_model_sequential() %>%
layer_embedding(input_dim = max_words + 1, output_dim = 16,
input_length = max_length) %>%
layer_conv_1d(filter = 32,
kernel_size = FLAGS$kernel_size1,
strides = FLAGS$strides1,
activation = "relu") %>%
layer_global_max_pooling_1d() %>%
layer_dense(units = 64, activation = "relu") %>%
layer_dense(units = 1, activation = "sigmoid")
model %>% compile(
optimizer = "adam",
loss = "binary_crossentropy",
metrics = c("accuracy")
)We target the hyperparameters we want to change by marking them as FLAGS$name. So in this model, we are tuning different values of kernel_size and strides, which are denoted by the kernel_size1 and strides1 flag, respectively.
Lastly, we must specify how the model is trained and evaluated.
history <- model %>%
fit(
x = kick_analysis,
y = state_analysis,
batch_size = 512,
epochs = 10,
validation_data = list(kick_assess, state_assess)
)
plot(history)
score <- model %>% evaluate(
kick_assess, state_assess
)
cat("Test accuracy:", score["accuracy"], "\n")This is mostly the same as what we have seen before. When we are running these different models, the scripts will be run in the environment they are initialized from, so the models will have access to objects like prepped_training and kickstarter_train, and we don’t have to create them inside the file.
Now that we have the file set up we need to specify the different hyperparameters we want to try. Three different values for the kernel size and two different values for the stride length give us 3 * 2 = 6 different runs.
hyperparams <- list(
kernel_size1 = c(3, 5, 7),
strides1 = c(1, 2)
)This is a small selection of hyperparameters and ranges. There is much more room for experimentation.
Now we have everything we need for hyperparameter searching. Load up tfruns and pass the name of the file we just created along with hyperparams to the tuning_run() function.
library(tfruns)
runs <- tuning_run(
file = "cnn-spec.R",
runs_dir = "_tuning",
flags = hyperparams
)
runs_results <- as_tibble(ls_runs())#> # A tibble: 6 × 24
#> run_dir eval_ metric_loss metric_accuracy metric_val_loss metric_val_accu…
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 _tuning/20… 1.03 0.0321 0.993 1.03 0.803
#> 2 _tuning/20… 1.01 0.0348 0.992 1.01 0.810
#> 3 _tuning/20… 0.992 0.044 0.989 0.992 0.804
#> 4 _tuning/20… 0.972 0.0286 0.995 0.972 0.814
#> 5 _tuning/20… 0.924 0.037 0.992 0.924 0.815
#> 6 _tuning/20… 0.967 0.0414 0.990 0.966 0.810
#> # … with 18 more variables: flag_kernel_size1 <dbl>, flag_strides1 <dbl>,
#> # epochs <dbl>, epochs_completed <dbl>, metrics <chr>, model <chr>,
#> # loss_function <chr>, optimizer <chr>, learning_rate <dbl>, script <chr>,
#> # start <dttm>, end <dttm>, completed <lgl>, output <chr>, source_code <chr>,
#> # context <chr>, type <chr>, NA. <dbl>You don’t have to, but we have manually specified the runs_dir argument, which is where the results of the tuning will be saved.
A summary of all the runs in the folder can be retrieved with ls_runs(); here we use as_tibble() to get the results as a tibble.
runs_results#> # A tibble: 6 × 24
#> run_dir eval_ metric_loss metric_accuracy metric_val_loss metric_val_accu…
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 _tuning/20… 1.03 0.0321 0.993 1.03 0.803
#> 2 _tuning/20… 1.01 0.0348 0.992 1.01 0.810
#> 3 _tuning/20… 0.992 0.044 0.989 0.992 0.804
#> 4 _tuning/20… 0.972 0.0286 0.995 0.972 0.814
#> 5 _tuning/20… 0.924 0.037 0.992 0.924 0.815
#> 6 _tuning/20… 0.967 0.0414 0.990 0.966 0.810
#> # … with 18 more variables: flag_kernel_size1 <dbl>, flag_strides1 <dbl>,
#> # epochs <dbl>, epochs_completed <dbl>, metrics <chr>, model <chr>,
#> # loss_function <chr>, optimizer <chr>, learning_rate <dbl>, script <chr>,
#> # start <dttm>, end <dttm>, completed <lgl>, output <chr>, source_code <chr>,
#> # context <chr>, type <chr>, NA. <dbl>We can condense the results down a little bit by only pulling out the flags we are looking at and arranging them according to their performance.
best_runs <- runs_results %>%
select(metric_val_accuracy, flag_kernel_size1, flag_strides1) %>%
arrange(desc(metric_val_accuracy))
best_runs#> # A tibble: 6 × 3
#> metric_val_accuracy flag_kernel_size1 flag_strides1
#> <dbl> <dbl> <dbl>
#> 1 0.815 5 1
#> 2 0.814 7 1
#> 3 0.810 3 1
#> 4 0.810 5 2
#> 5 0.804 3 2
#> 6 0.803 7 2There isn’t much performance difference between the different choices but using kernel size of 5 and stride length of 1 narrowly came out on top.
10.7 Cross-validation for evaluation
In Section 8.5, we saw how we can use resampling to create cross-validation folds for evaluation. The Kickstarter data set we are using is big enough that we have ample data for a single training set, validation set, and testing set that all contain enough observations in them to give reliable performance metrics. However, it is important to understand how to implement other resampling strategies for situations when your data budget may not be as plentiful or when you need to compute performance metrics that are more precise.
set.seed(345)
kick_folds <- vfold_cv(kickstarter_train, v = 5)
kick_folds#> # 5-fold cross-validation
#> # A tibble: 5 × 2
#> splits id
#> <list> <chr>
#> 1 <split [161673/40419]> Fold1
#> 2 <split [161673/40419]> Fold2
#> 3 <split [161674/40418]> Fold3
#> 4 <split [161674/40418]> Fold4
#> 5 <split [161674/40418]> Fold5Each of these folds has an analysis or training set and an assessment or validation set. Instead of training our model one time and getting one measure of performance, we can train our model v times and get v measures (five, in this case), for more reliability.
Last time we saw how to create a custom function to handle preprocessing, fitting, and evaluation. We will use the same approach of creating the function, but this time use the model specification from Section 10.2.
fit_split <- function(split, prepped_rec) {
## preprocessing
x_train <- bake(prepped_rec, new_data = analysis(split),
composition = "matrix")
x_val <- bake(prepped_rec, new_data = assessment(split),
composition = "matrix")
## create model
y_train <- analysis(split) %>% pull(state)
y_val <- assessment(split) %>% pull(state)
mod <- keras_model_sequential() %>%
layer_embedding(input_dim = max_words + 1, output_dim = 16,
input_length = max_length) %>%
layer_conv_1d(filter = 32, kernel_size = 5, activation = "relu") %>%
layer_global_max_pooling_1d() %>%
layer_dense(units = 64, activation = "relu") %>%
layer_dense(units = 1, activation = "sigmoid") %>%
compile(
optimizer = "adam",
loss = "binary_crossentropy",
metrics = c("accuracy")
)
## fit model
mod %>%
fit(
x_train,
y_train,
epochs = 10,
validation_data = list(x_val, y_val),
batch_size = 512,
verbose = FALSE
)
## evaluate model
keras_predict(mod, x_val, y_val) %>%
metrics(state, .pred_class, .pred_1)
}We can map() this function across all our cross-validation folds. This takes longer than our previous models to train, since we are training for 10 epochs each on 5 folds.
cv_fitted <- kick_folds %>%
mutate(validation = map(splits, fit_split, kick_prep))
cv_fitted#> # 5-fold cross-validation
#> # A tibble: 5 × 3
#> splits id validation
#> <list> <chr> <list>
#> 1 <split [161673/40419]> Fold1 <tibble [4 × 3]>
#> 2 <split [161673/40419]> Fold2 <tibble [4 × 3]>
#> 3 <split [161674/40418]> Fold3 <tibble [4 × 3]>
#> 4 <split [161674/40418]> Fold4 <tibble [4 × 3]>
#> 5 <split [161674/40418]> Fold5 <tibble [4 × 3]>Now we can use unnest() to find the metrics we computed.
cv_fitted %>%
unnest(validation)#> # A tibble: 20 × 5
#> splits id .metric .estimator .estimate
#> <list> <chr> <chr> <chr> <dbl>
#> 1 <split [161673/40419]> Fold1 accuracy binary 0.824
#> 2 <split [161673/40419]> Fold1 kap binary 0.648
#> 3 <split [161673/40419]> Fold1 mn_log_loss binary 0.908
#> 4 <split [161673/40419]> Fold1 roc_auc binary 0.872
#> 5 <split [161673/40419]> Fold2 accuracy binary 0.824
#> 6 <split [161673/40419]> Fold2 kap binary 0.647
#> 7 <split [161673/40419]> Fold2 mn_log_loss binary 0.899
#> 8 <split [161673/40419]> Fold2 roc_auc binary 0.872
#> 9 <split [161674/40418]> Fold3 accuracy binary 0.827
#> 10 <split [161674/40418]> Fold3 kap binary 0.653
#> 11 <split [161674/40418]> Fold3 mn_log_loss binary 0.899
#> 12 <split [161674/40418]> Fold3 roc_auc binary 0.877
#> 13 <split [161674/40418]> Fold4 accuracy binary 0.824
#> 14 <split [161674/40418]> Fold4 kap binary 0.647
#> 15 <split [161674/40418]> Fold4 mn_log_loss binary 0.910
#> 16 <split [161674/40418]> Fold4 roc_auc binary 0.872
#> 17 <split [161674/40418]> Fold5 accuracy binary 0.827
#> 18 <split [161674/40418]> Fold5 kap binary 0.651
#> 19 <split [161674/40418]> Fold5 mn_log_loss binary 0.912
#> 20 <split [161674/40418]> Fold5 roc_auc binary 0.875We can summarize the unnested results to match what we normally would get from collect_metrics()
cv_fitted %>%
unnest(validation) %>%
group_by(.metric) %>%
summarize(
mean = mean(.estimate),
n = n(),
std_err = sd(.estimate) / sqrt(n)
)#> # A tibble: 4 × 4
#> .metric mean n std_err
#> <chr> <dbl> <int> <dbl>
#> 1 accuracy 0.825 5 0.000694
#> 2 kap 0.649 5 0.00125
#> 3 mn_log_loss 0.906 5 0.00277
#> 4 roc_auc 0.874 5 0.00101The metrics have little variance just like they did last time, which is reassuring; our model is robust with respect to the evaluation metrics.
10.8 The full game: CNN
We’ve come a long way in this chapter, and looked at the many different modifications to the simple CNN model we started with. Most of the alterations didn’t add much so this final model is not going to be much different than what we have seen so far.
There are an incredible number of ways to change a deep learning network architecture, but in most realistic situations, the benefit in model performance from such changes is modest.
10.8.1 Preprocess the data
For this final model, we are not going to use our separate validation data again, so we only need to preprocess the training data.
max_words <- 2e4
max_length <- 30
kick_rec <- recipe(~ blurb, data = kickstarter_train) %>%
step_tokenize(blurb) %>%
step_tokenfilter(blurb, max_tokens = max_words) %>%
step_sequence_onehot(blurb, sequence_length = max_length)
kick_prep <- prep(kick_rec)
kick_matrix <- bake(kick_prep, new_data = NULL, composition = "matrix")
dim(kick_matrix)#> [1] 202092 3010.8.2 Specify the model
Instead of using specific validation data that we can then compute performance metrics for, let’s go back to specifying validation_split = 0.1 and let the Keras model choose the validation set.
final_mod <- keras_model_sequential() %>%
layer_embedding(input_dim = max_words + 1, output_dim = 16,
input_length = max_length) %>%
layer_conv_1d(filter = 32, kernel_size = 7,
strides = 1, activation = "relu") %>%
layer_global_max_pooling_1d() %>%
layer_dense(units = 64, activation = "relu") %>%
layer_dense(units = 1, activation = "sigmoid")
final_mod %>%
compile(
optimizer = "adam",
loss = "binary_crossentropy",
metrics = c("accuracy")
)
final_history <- final_mod %>%
fit(
kick_matrix,
kickstarter_train$state,
epochs = 10,
validation_split = 0.1,
batch_size = 512,
verbose = FALSE
)
final_history#>
#> Final epoch (plot to see history):
#> loss: 0.0295
#> accuracy: 0.994
#> val_loss: 0.7687
#> val_accuracy: 0.8555This looks promising! Let’s finally turn to the testing set, for the first time during this chapter, to evaluate this last model on data that has never been touched as part of the fitting process.
kick_matrix_test <- bake(kick_prep, new_data = kickstarter_test,
composition = "matrix")
final_res <- keras_predict(final_mod, kick_matrix_test, kickstarter_test$state)
final_res %>% metrics(state, .pred_class, .pred_1)#> # A tibble: 4 × 3
#> .metric .estimator .estimate
#> <chr> <chr> <dbl>
#> 1 accuracy binary 0.851
#> 2 kap binary 0.702
#> 3 mn_log_loss binary 0.773
#> 4 roc_auc binary 0.895This is our best-performing model in this chapter on CNN models, although not by much. We can again create an ROC curve, this time using the test data in Figure 10.11.
final_res %>%
roc_curve(state, .pred_1) %>%
autoplot()
FIGURE 10.11: ROC curve for final CNN model predictions on testing set of Kickstarter campaign success
We have been able to incrementally improve our model by adding to the structure and making good choices about preprocessing. We can visualize this final CNN model’s performance using a confusion matrix as well, in Figure 10.12.
final_res %>%
conf_mat(state, .pred_class) %>%
autoplot(type = "heatmap")
FIGURE 10.12: Confusion matrix for final CNN model predictions on testing set of Kickstarter campaign success
Notice that this final model performs better then any of the models we have tried so far in this chapter, Chapter 8, and Chapter 9.
For this particular data set of short text blurbs, a CNN model able to learn local features performed the best, better than either a densely connected neural network or an LSTM.
10.9 Summary
CNNs are a type of neural network that can learn local spatial patterns. They essentially perform feature extraction, which can then be used efficiently in later layers of a network. Their simplicity and fast running time, compared to models like LSTMs, makes them excellent candidates for supervised models for text.
10.9.1 In this chapter, you learned:
how to preprocess text data for CNN models
about CNN network architectures
how CNN layers can be stacked to extract patterns of varying detail
how byte pair encoding can be used to tokenize for finer detail
how to do hyperparameter search in Keras with tfruns
how to evaluate CNN models for text
References
The explanations of the second label would just be the inverse of the first label. If you have more than two labels, it makes sense to explore some or all of them.↩︎